Как устроены QR коды
Изначально я хотел написать статью про коды Рида-Соломона с иллюстрацией на примере работы QR-кодов, в процессе подготовки сделал инструмент для упрощения визуализации и обнаружил, что у меня уже есть достаточно отсутствующего на Хабре материала, в связи с чем поменял план. Кому не интересно читать, QR с КДПВ сгенерированы с помощью qr-verbose.
pip install qr-verboseДокументация (англ.)
Про QR-коды на Хабре писали много, например одна из самых популярных статей за всё время — “Читаем QR код” и куча переводных статей. К сожалению, у этих статей есть кое-что общее: если вы попытаетесь прочитать код версии 4 и больше, а также некоторые коды версии 3, следуя описанию из статей, то потерпите фиаско. Не верите? Попробуйте прочитать нижний код из КДПВ.
В статье напомню, как устроен QR-код и какие проблемы начинаются с версии 3, а также надеюсь, что qr-verbose поможет разобраться тем, кто ещё не разобрался.
Как читать QR код, опять
Итак, берём QR-код.
qr-verbose -m 0 -v 3 \
-t regular \
-e M \
-o a_zachem_regular.png \
t.me/a_zachem_eto_nuzhno
Сначала определяем метаданные
qr-verbose -m 0 -v 3 \
-t color \
-e M \
-o a_zachem_colors.png \
t.me/a_zachem_eto_nuzhno
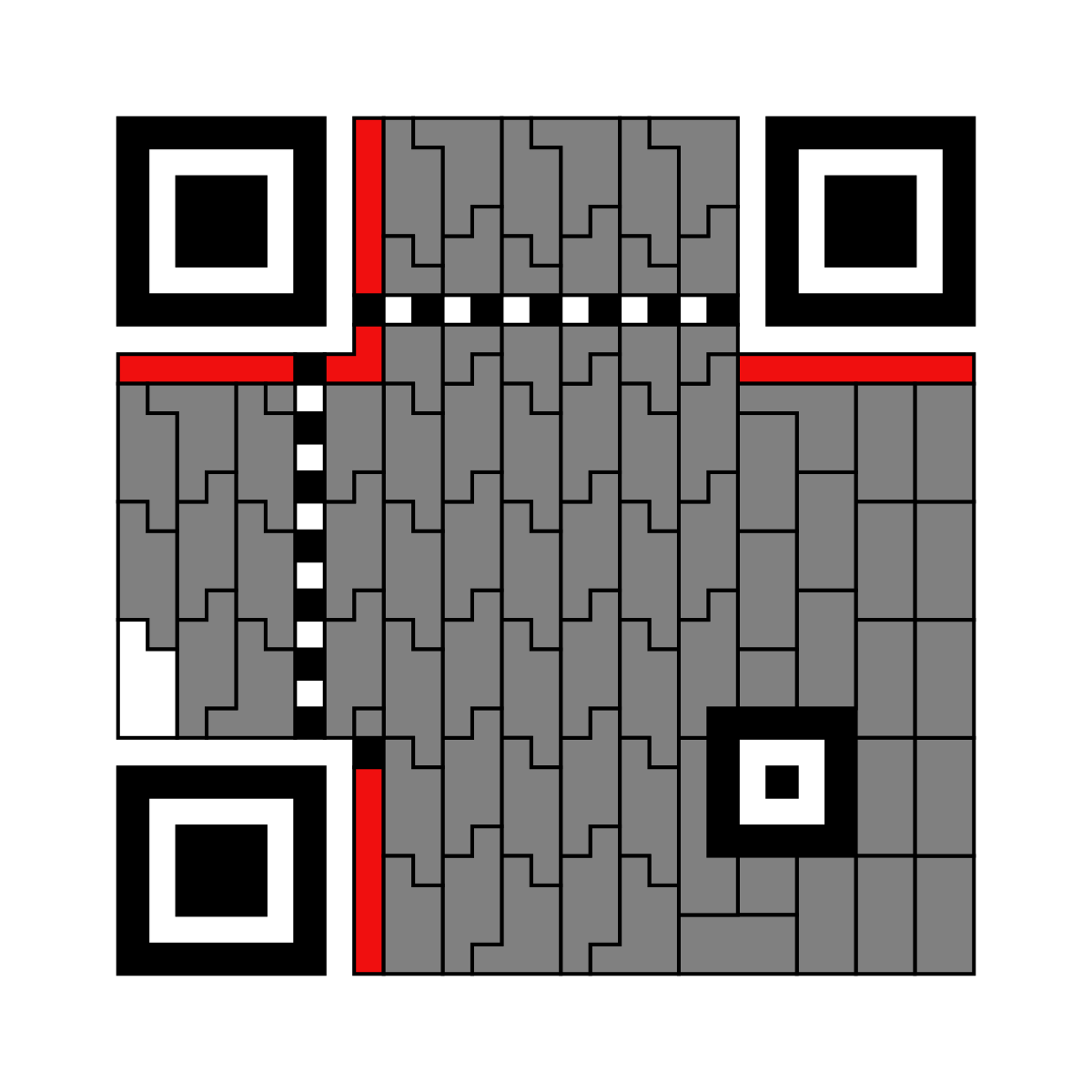
Итак, на что здесь стоит смотреть:
3 больших красных квадрата - шаблон поиска, эти квадраты всегда обрамлены белой границей
Черно-белые полоски, обрамленные фиолетовой границей, — информация об уровне коррекции ошибок и маске данных. Уровней коррекции ошибок всегда 4: L (~7%), M (~15%), Q (~25%), H (~30%), в скобках указана доля ошибок, которую можно восстановить. Доля символов коррекции в два раза больше указанной. Маска — один из 8 шаблонов флипа данных, маска предназначена для исключения из итогового QR-кода шаблонов, запутывающих сканеры. Первые 2 бита отвечают за уровень коррекции 01-L, 00-M, 11-Q, 10-H. В нашем случае это M. Биты 2–4 задают маску, оставшиеся 10 бит — биты коррекции систематического кода BCH(15, 5); наконец, нужно эти 15 бит поксорить с определённой в стандарте константой
10101 00000 10010, и получившиеся биты записать. Все эти 15 бит дублируются, номера отмечают индекс бита.Горизонтальная и вертикальная полоски с чередующимися битами красно-лилового цвета, соединяющие большие квадраты, — это тайм-шаблон, предназначенный для удобного получения информации о размере кода; в этих полосках номера бит отсутствуют.
Зелёный квадрат — шаблон выравнивания; также служит для помощи при сканировании.
Оранжевый квадрат из 4 бит в правом нижнем углу — начало данных, к нему применяется маска и он участвует в формировании блоков коррекции ошибок, как и все последующие данные. В этих 4 битах хранится информация о методе представления данных. В нашем случае это режим по умолчанию — байтовый ввод.
Следующий за ним фиолетовый блок из 8 бит содержит информацию о длине закодированного сообщения; так же, как и информация о режиме кодирования, он подвержен маскированию и участвует в формировании блоков коррекции ошибок.
Оставшиеся участки QR-кода разбиты на блоки по 8 бит (за исключением одного блока из 4 бит), из которых образуются байты. Синие байты — исходные данные, жёлтые — байты коррекции ошибок. Блоки данных с красной границей — реальные исходные данные, с зелёной — паддинг.
Внутри каждого байта подпись в формате <индекс_байта>:<индекс_бита>. Байты нумеруются в порядке змейки (правый рисунок), биты — в порядке движения, сначала обрабатывая правый бит (рисунок слева).

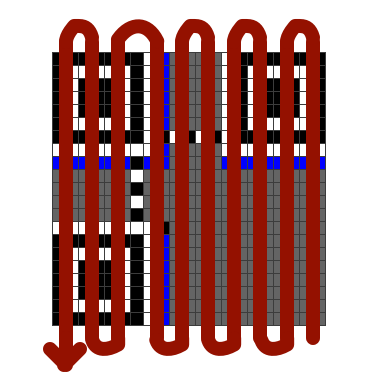
Едем дальше, давайте уберём маску
qr-verbose -m -1 -v 3 \
-t color \
-e M \
-o a_zachem_colors.png \
t.me/a_zachem_eto_nuzhno
Обратите внимание, что теперь оставшиеся 7 бит слева над нижним красным квадратом стали нулевыми, режим кодирования 0100 соответствует байтовому кодированию, в длине записано число 24 (отмечу, что 0 соответствует старшему биту, но конкретно для числа 24 это не имеет значения), а 24-й блок содержит 4 нулевых бита — это стандартный нулевой терминатор; после него идут паддинговые байты одного из двух значений: 17, 236. А вот и более наглядно с переводом в ASCII: попутно добавляю лого, чтобы было видно, какие байты оно закрывает (да, лого именно закрывает байты; QR-код всё ещё можно просканировать за счёт кодов дополнительных байтов избыточности кода Рида-Соломона, хотя предназначались они не для этого).

Что происходит начиная с версии 3
Давайте посмотрим на код из КДПВ и проделаем для него всё то же самое, что делали выше.
qr-verbose -m -1 -v 3 \
-t ascii \
-e Q \
-o misterious_ascii.png \
"Happy new year, Habr!"
Как же так? Раньше там была вполне содержательная информация: жалкая попытка незаметно впихнуть рекламу личного блога, а теперь просто какая-то билиберда. Проблема возникает на этапе построения кодов Рида-Соломона, если быть точнее, то на этапе разбиения и укладки данных. Дело в том, что, как и с BCH(15, 5) кодом, так и с кодом Рида-Соломона в QR используется систематическое кодирование — это когда исходное сообщение является частью закодированного сообщения, что и позволяет прочитать сообщение в предыдущем случае, просто игнорируя то, что записано в дополнительных байтах. У кодов Рида-Соломона есть ограничение на размер блока данных: если код построен над полем \(\mathbb{F}_q\), то блок не может быть размером больше \(q\). В QR-кодах Рид-Соломон работает над полем \(\mathbb{F}_{256}\) — самым удобным с практической точки зрения; это накладывает ограничение размера блока в 256 элементов. Решение этой проблемы оказалось простым: данные образуют не один блок коррекции, а несколько, и как раз впервые два блока появляются в QR-коде версии 3 с уровнем кодирования Q. На этом этапе уже важно понимать, как именно происходит кодирование, по крайней мере часть про разбиение данных.
Во-первых, кодирование происходит не на байтах, из которых составлены символы; вместо этого они заново нарезаются по байтам, начиная с данных режима кодирования и заканчивая нулевым терминатором. Следующая картинка показывает, как это происходит.
По сути большинство байтов, из которых сформировано избыточное кодирование, состоят из двух половинок байтов кодирования реальных данных. Последний штрих — это ещё один вспомогательный механизм защиты от ошибок — interleaving. Это стандартная техника для защиты от нескольких подряд идущих ошибок: данные из разных блоков перемешиваются, что уменьшает вероятность того, что все потери будут приходиться на один блок. В случае QR-кодов interleaving блоков довольно простой: сначала по очереди идут первые байты блоков, потом в том же порядке — вторые байты и так далее. Отличная иллюстрация есть в статье Взлом Bitcoin по телевизору: обфускуй, не обфускуй, все равно получим QR:

При совмещении этой техники с тем фактом, что байты при избыточном кодировании содержат информацию о двух байтах данных, мы получаем, что они разносятся по разным участкам; из-за этого прочитать данные становится труднее. На следующей картинке отмечено, как на самом деле располагаются символы в коде выше.

На этом всё, спасибо за внимание и с Новым годом!